16 March, 2026

In 2026, users no longer just click blue links; they get instant answers from AI. If your website lacks an llms.txt file, you are essentially invisible to these AI agents.
What is it? Think of llms.txt as a "handshake" protocol. It’s a simple text file in your website's root directory that tells AI agents (like Gemini or Perplexity) exactly what content they can index and how to interpret your brand.
Why it matters:
Stop the "Zero-Click" Decline: AI agents pull data from structured sources. Without this file, they often ignore your site or hallucinate your content.
Gain Authority: AI models prioritize "preferred sources" that provide machine-readable context.
Control Your Brand: You decide which parts of your site AI agents can use and how they should attribute that data to you.
The Bottom Line:
You don't need a massive technical overhaul, but you do need to be "AI-readable." Implementing llms.txt is the fastest way to transition from a generic website to a cited, authoritative source in AI-generated answers.
The way people search for information is changing fast. AI agents now answer questions, recommend products, and summarize topics without users ever clicking a link. If your website is invisible to these AI systems, you're already losing ground.
The llms.txt file is a new protocol designed to help AI crawlers discover, read, and understand your website content. Think of it as a handshake between your site and the AI models that increasingly shape how people find information online.
Most websites were built to communicate with traditional search engines like Google. They use sitemaps, meta tags, and robots.txt files. But AI agents operate differently. They need structured, machine-readable instructions that tell them exactly what content is available and how it should be interpreted. Without an llms.txt file, your website is essentially locked behind a door that AI agents don't know how to open.
This guide explains what llms.txt is, how it differs from robots.txt, and exactly how to implement it on your website. Whether you're a business owner, marketer, or developer, understanding this protocol is critical to staying visible in the age of AI search. If you've been tracking the zero-click crisis reshaping AI visibility, the llms.txt handshake is your next step.
The llms.txt file is a proposed protocol that provides AI agents and large language model crawlers with structured instructions about your website. It tells AI systems what content exists, what they can access, and how that content should be interpreted.
Think of it as a welcome mat designed specifically for AI. While robots.txt has served as the gatekeeper for traditional web crawlers for decades, the llms.txt protocol addresses a fundamentally different audience. AI agents don't just crawl pages for links and keywords; they need to understand context, content boundaries, and permissions in a format optimized for machine comprehension.
Why does this matter now? AI search is no longer hypothetical. Tools powered by large language models are already pulling information from across the web to generate answers and recommendations. If your website lacks an llms.txt file, these systems may skip your content entirely or misinterpret it. The llms.txt protocol gives you direct control over how AI agents interact with your site.
For businesses investing in long-term digital visibility, this protocol is foundational. The team at iSyncEvolution has been monitoring how AI web crawling protocols are reshaping search, and llms.txt sits at the center of that shift.
Here's a hard truth: most websites today are completely invisible to AI agents. Not because the content is bad, but because AI crawlers simply can't access or interpret it properly.
Traditional websites are built for humans and search engine bots like Googlebot. They rely on HTML structures, JavaScript rendering, and metadata that search engines have processed for two decades. But AI agents work on a different paradigm. They look for explicit, structured signals that tell them what content is available and how it should be consumed.
Several factors contribute to this invisibility:
The result is a growing gap between websites that AI agents can read and recommend, and those that remain effectively invisible.
Understanding how AI agents read websites requires comparing them with systems we already know. The way content is discovered, crawled, and indexed varies significantly between traditional search engines and AI-powered systems.
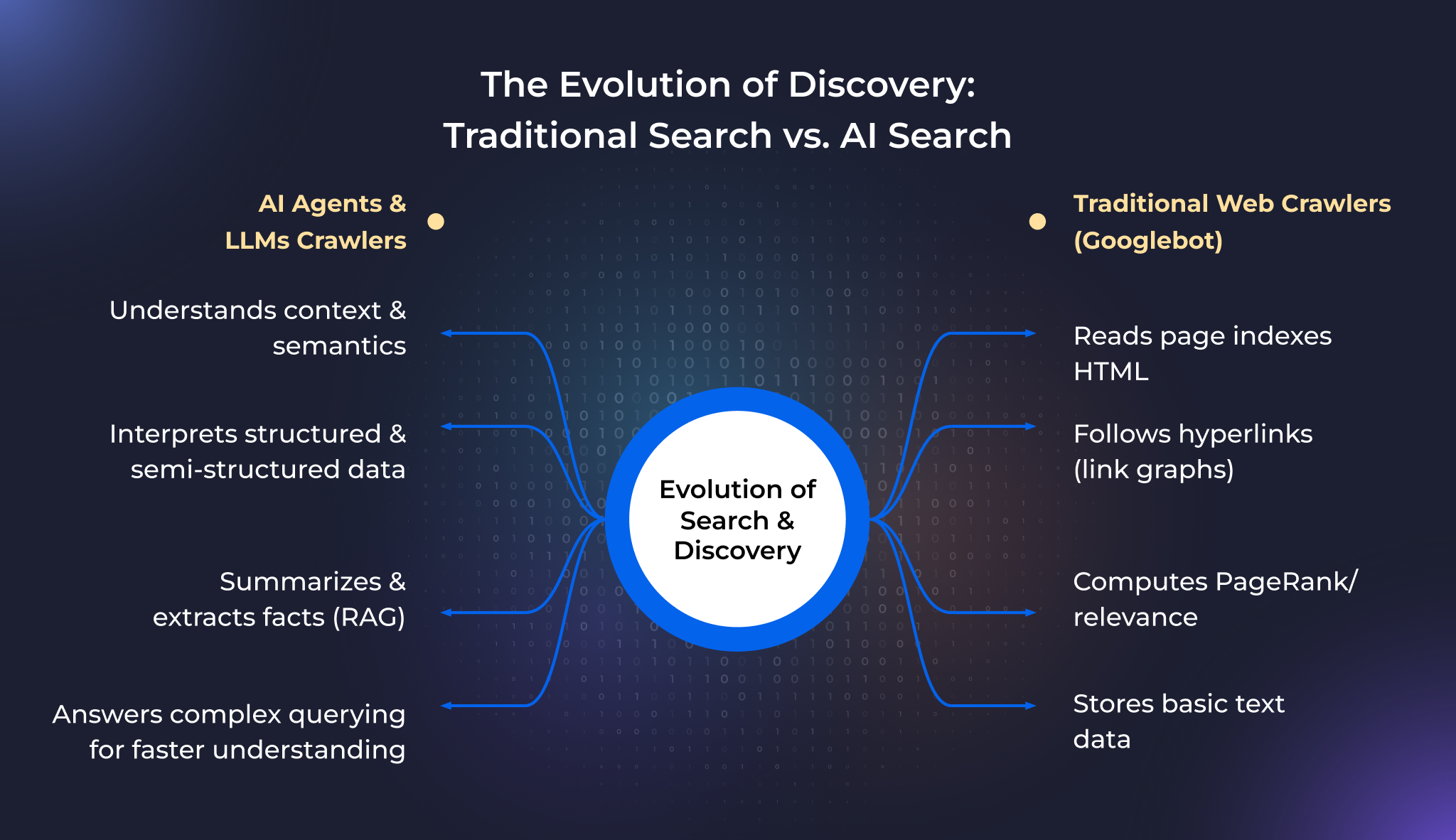
Traditional crawlers like Googlebot follow links across the web, download HTML pages, render JavaScript when needed, and index content based on relevance signals like keywords, backlinks, and page structure.
Googlebot relies on robots.txt to understand which pages it can crawl. It uses sitemaps to discover new pages efficiently. It interprets meta tags, canonical URLs, and structured data to determine how content should appear in search results.
However, Googlebot's primary purpose is to rank pages for human searchers. It doesn't need to "understand" content the way an AI agent does; it matches queries to pages. AI agents do something fundamentally different.
AI agents approach websites with a different goal. Instead of ranking pages, they extract, comprehend, and synthesize information. When an AI agent visits your website, it's not looking for the best page to link to; it's looking for content it can absorb and use to generate answers.
This is where the llms.txt protocol becomes essential. AI crawlers need explicit signals about:
Without these signals, AI agents must guess. When they guess, they often get it wrong or move on to a site that provides clear instructions.
AI systems aren't browsers. They don't see your homepage design, images, or interactive elements. They process text, structure, and metadata. When an AI agent encounters a website, it needs clear, parseable instructions to operate efficiently.
Machine-readable instructions like llms.txt serve several purposes:
For businesses looking to stay ahead, working with an experienced SEO team that understands AI search optimization is becoming increasingly important.
One of the most common questions in AI search optimization: What's the difference between robots.txt and llms.txt? Both files sit in your website's root directory and provide instructions to automated systems, but they serve fundamentally different purposes.
Robots.txt was created in 1994 as a standard for communicating with traditional web crawlers. It tells bots which pages they can crawl and which to avoid using simple directives like `User-agent`, `Allow`, and `Disallow`.
Llms.txt is designed specifically for AI agents and LLM crawlers. Rather than just controlling access, it provides structured information about your site's content, context, and intended use by AI systems.
| Feature | robots.txt | llms.txt |
|---|---|---|
| Audience | Traditional search engine crawlers | AI agents and LLM crawlers |
| Purpose | Control crawl access | Guide AI content interpretation |
| Content | Allow/Disallow directives | Structured content descriptions and permissions |
| Scope | Page-level access control | Content-level AI indexing guidance |
| Standard | Established in 1994 | Emerging protocol |
Do AI crawlers use robots.txt? Some do respect its directives. But robots.txt wasn't built for them and doesn't provide the context or permissions AI systems need.
The key takeaway: robots.txt and llms.txt are complementary, not interchangeable. You need both. Understanding this difference is essential for any comprehensive SEO strategy moving forward.
When an AI agent visits your website and finds an llms.txt file, a structured exchange of information takes place. This handshake determines whether your content becomes part of the AI's knowledge base or gets ignored.
Here's how the process works:
Without the llms.txt file, there's no handshake. The AI agent has no structured way to understand your site and moves on. This level of control is something that generative AI in digital marketing has made not just useful, but necessary.
Implementing llms.txt is straightforward but requires careful thought about what content you want AI agents to access. Here's a step-by-step guide to configure llms.txt for AI indexing.
Create a plain text file named `llms.txt`. At a minimum, include:
Keep the format clean and consistent. AI agents parse this file programmatically.
This is where llms.txt goes beyond robots.txt. Explicitly define what AI agents can do with your content:
Place your completed llms.txt file in the root directory. It should be accessible at `yourdomain.com/llms.txt`.
Ensure:
After placing the file, verify it works:
Implementing llms.txt is an ongoing process, much like maintaining your robots.txt. The iSyncEvolution team recommends treating your llms.txt file as a living document that evolves with your content strategy.
The shift toward AI-driven search isn't a trend; it's a structural change in how information is discovered and consumed. As AI agents become the primary interface between users and the web, websites that fail to communicate with these systems will lose visibility at an accelerating rate.
Files like llms.txt will become essential because:
Working with a team that understands both traditional SEO and AI visibility, like iSyncEvolution's SEO services, ensures you're prepared for both current and future search landscapes.
Your website's visibility is no longer determined solely by Google rankings. AI agents are reshaping how people find and consume information, and the llms.txt file bridges the gap between your content and these AI systems.
Without an llms.txt file, your website remains invisible to AI crawlers that increasingly power search, recommendations, and automated research. The handshake never happens. Your content stays locked behind a door AI agents can't open.
Implementing llms.txt requires understanding what AI agents need and how they differ from traditional crawlers. From creating the file to defining access policies and testing accessibility, every step moves you closer to being part of the AI-driven web.
The llms.txt protocol is still emerging, which makes now the ideal time to implement it. The websites that establish their content in AI knowledge bases today will maintain visibility, while others struggle to catch up tomorrow.

The llms.txt file provides AI agents and LLM crawlers with structured instructions about your website content. It tells AI systems what content is available, what they can access, and how to interpret it for AI search indexing.
robots.txt controls which pages traditional crawlers can access. llms.txt provides AI agents with content descriptions, permissions, and context for how to use your content, going beyond simple access control.
Yes. They serve different audiences. robots.txt manages traditional search engine crawlers, while llms.txt communicates directly with AI agents. Both are necessary for comprehensive search visibility.
Place it in your website's root directory so it's accessible at `yourdomain.com/llms.txt`. Ensure it returns a 200 HTTP status code and isn't blocked by server rules.
While llms.txt significantly improves your chances of being indexed by AI systems, visibility also depends on content quality, relevance, and how AI agents prioritize sources. It's a critical first step, not a guarantee.
Nikhil Shah is the CTO and Co-Founder of iSyncEvolution, an engineering leader who aligns modern technology best practices with long-term commercial success. A veteran of cloud infrastructure and scalable web/mobile solutions, he specializes in building high-performance software environments. Nikhil helps global brands master their technical roadmaps, optimizing both code performance and development economics to fuel growth.
© 2026 iSyncEvolution Pvt Ltd. All Rights Reserved.
